Tutorial: Writing JAX-like code in PyTorch with functorch
The majority of deep learning frameworks are organized around a clear object-oriented (OO) philosophy, in which the parameters and logic of each component are neatly encapsulated inside an object (e.g., the nn.Module of PyTorch or the keras.Model of TensorFlow). A small number of frameworks - most notably JAX - have embraced instead a pure functional programming (FP) perspective. The FP approach has two major advantanges, which are not immediately apparent. On one side, parameters live outside the models, making it very easy to manipulate them in-between function calls.1 On the other side, it is simple to concatenate functional transformations on our model to obtain very sophisticated behaviours.2
JAX in particular has steadily gained popularity in many fields requiring more flexibility than the standard OO frameworks, leading to an explosion of projects to combine the two worlds and bring some form of PyTorch-like functionalities in JAX (e.g., Flax, Haiku, Objax, Equinox). In this blog post, we go into the opposite direction, and we take a sneak peek at functorch, a prototype library under development to provide users the possibility of writing JAX-like code using standard PyTorch.
🔗 The code for this tutorial is available on a Colab notebook: https://colab.research.google.com/drive/1Oi-6q6w9QdaE4Bx_rAzcspGJVclqbnW7?usp=sharing (
functorchbeing under development means that most likely the code will break very soon, or is already broken).
Outline of the tutorial
To highlight the differences between PyTorch and JAX, it is helpful to look at specific examples. For this tutorial, we look at a toy multi-view scenario: given an image model, we want to develop a new model that works on a set of images, corresponding to different views of the same input. While this can be done in many ways, the vmap (vectorized map) function from JAX is particularly elegant.
To this end, we show three implementations: JAX (easy), PyTorch (harder), and finally functorch (much easier). In moving from PyTorch to JAX, we need to transform the objects representing our neural networks into (pure) functions. As an added bonus, we show a simplified solution for how functorch itself tackles the issue.
⚡ In this tutorial, we see how to use JAX-like programming in PyTorch. As a companion (writing PyTorch-like code in JAX), I strongly suggest From PyTorch to JAX: towards neural net frameworks that purify stateful code from Sabrina Mielke.
Warming up
Let us start with a tiny convolutional neural network (CNN):
tinycnn = nn.Sequential(
nn.Conv2d(3, 5, kernel_size=3),
nn.Conv2d(5, 5, kernel_size=3)
)
Nothing out of the ordinary. For completeness, let us run the CNN on a random 16x16 RGB image:
x = torch.randn((1, 3, 16, 16))
y = tinycnn(x)
We say that models in PyTorch are stateful, because the result of the last line will depend on the internal parameters of the module, which in turn depend on the context of the execution (e.g., calls to optimizer.step() can modify their values as a side effect).
Now, suppose we are asked to implement a multi-view variant of the CNN, i.e., a CNN taking as input several photos of the same object, where for simplicity we will assume a fixed number of views. A common solution to multi-view problems is to process each image with a shared CNN, then pool the results using, e.g., max-pooling, to obtain a representation which is independent on the order of the views:3
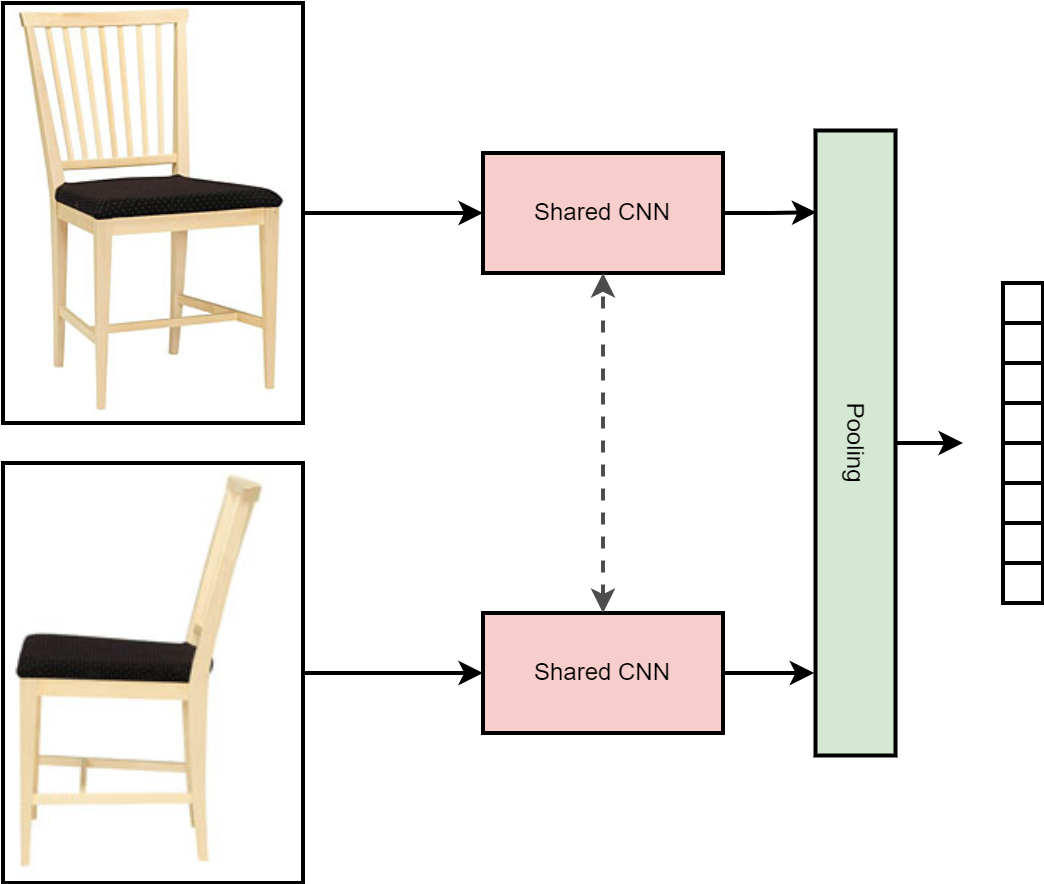
Concretely, we represent our multi-view dataset by adding a trailing dimension to our input tensor, representing the views of the same input:
x = torch.randn((
1, # Batch dimension
3, # Channels
16, # Width
16, # Height
5 # Views
))
Applying a CNN on a new dimension requires to vectorize its operations along the new axis, something which calls to mind the vmap transform from JAX. To investigate this, let us see how this problem would be implemented in pure JAX.4
Solution 1: JAX with vmap
We use the stax module from JAX to re-implement the same neural network above:
tinycnn_init, tinycnn_apply = stax.serial(
stax.Conv(5, (3,3)),
stax.Conv(5, (3,3))
)
Because JAX fully embraces the functional paradigm, a model is not represented as an instance of an object. Instead, it is represented with a pair of functions to, respectively, initialize the model and apply it. The model application is stateless, because we explicitly need to pass the parameters to run the model (pure functions not being allowed to have side effects):
key = jax.random.PRNGKey(42)
_, params = tinycnn_init(key, (-1, 16, 16, 3)) # Channels last
x = jax.random.normal(key, (3, 16, 16, 3))
y = tinycnn_apply(params, x)
The advantage of working with functions is that it is very easy to transform them into other functions. For example, we can vectorize our tinycnn_apply function on our new axis, to work on the multi-view tensor:
tinycnn_apply_multiview = jax.vmap(partial(tinycnn_apply, params), in_axes=4, out_axes=4)
It works out the box:
x = jax.random.normal(key, (1, 16, 16, 3, 5))
print(tinycnn_apply_multiview(X).shape)
# Out: (3, 12, 12, 5, 5)
Can we replicate this in PyTorch?
Solution 2: PyTorch with vmap
PyTorch already has a number of prototype implementations of JAX functionalities, including a vmap prototype, and a functional autograd API. However, both modules work on pure functions, while PyTorch modules are classes. This requires, basically, to “extract” the forward method of the module and “purify” it by making the parameters an explicit argument. Let me steal the following image with a reminder to read this fantastic blog post:
When the autograd Functional API was released, I asked about its inter-operability on the PyTorch forum, and one of the developers of the API suggested the following transformation (simplified for readability, see the associated notebook):
def make_functional(module):
orig_params = tuple(module.parameters())
# Remove all the parameters in the model
names = []
for name, p in list(module.named_parameters()):
del_attr(module, name.split("."))
names.append(name)
# This is equivalent to the "tinycnn_apply" function above
def functional_module_fw(params, x):
for name, p in zip(names, params):
set_attr(module, name.split("."), p)
return module(x)
return orig_params, functional_module_fw
What the transformation does is lifting the parameters from inside the module, and defining a function taking them as input.5 Now we can call the function just like in JAX:
params, model_fcn = make_functional(tinycnn)
x = torch.randn((1, 3, 16, 16))
y = model_fcn(params, x)
More importantly, now that we have a pure function, we can use the PyTorch vmap! The next instructions are almost line-by-line identical to JAX:
model_fcn_multiview = torch.vmap(partial(model_fcn, params), in_dims=4, out_dims=4)
x = torch.randn((1, 3, 16, 16, 5))
print(model_fcn_multiview(X).shape)
# Out: (1, 12, 12, 5, 5)
Solution 3: functorch, finally
Although it works, it is tricky, and it also breaks down in some situations (e.g., if a layer has buffers like batch normalization, we need to extract those independently). However, if you run the code above, you will get an interesting warning, telling you that the development of these functional tools has moved to a separate project, functorch (see also #42368 RFC: torch.vmap and related issues).
functorch is interesting because it promises to be an almost complete porting of JAX functionalities inside PyTorch. To begin with, it has its own, more professional version of make_functional:
import functorch
model_fcn, params = functorch.make_functional(tinycnn)
It has a more advanced version of vmap, with several improvements over the (now deprecated) variant in PyTorch:
model_fcn_multiview = functorch.vmap(partial(model_fcn, params), in_dims=4, out_dims=4)
print(model_fcn_multiview(x).shape)
# Out: (1, 12, 12, 5, 5)
Apart from vmap, functorch has its own implementation of grad, vjp, and jacrev, along with a variant of make_functional that works also with buffers, and some additional methods apparently under way.
These can be composed like in JAX to, e.g., obtain the Jacobian of the multi-view function:
jacobian_fcn = jacrev(model_fcn_multiview)
This is it for the tutorial! functorch is still under development, but it promises to be an interesting middle ground for users wanting only a “tiny bit of JAX” in their PyTorch applications. If you are intrigued, you should definitely go take a look!
Liked the tutorial? Remember that you can follow me on Twitter for almost daily updates. Feel free to reach out for ideas, feedbacks, or comments of any kind.
Footnotes and references
-
This is incredibly useful when moving beyond pure first-order optimization. For example, two years ago I was playing with an optimization method called successive convex approximations, which required (among other things) to compute an expression of the form \(w^\top A w\), for some matrix \(A\) and network’s parameters \(w\). Using JAX’s pytrees, this was trivial. ↩
-
Consider the classical example
jacfwd(jacrev(f))of composing forward-over-reverse automatic differentiation to compute dense Hessians. A personal example here (from the same paper as footnote 1) was linearizing a network \(f\) and then repeatedly computing the product with several vectors \(v\), which is even a primitive in JAX. ↩ -
Su, H., Maji, S., Kalogerakis, E. and Learned-Miller, E., 2015. Multi-view convolutional neural networks for 3d shape recognition. IEEE ICCV (pp. 945-953). ↩
-
🧠 Since this is a toy problem, we can of course implement the multi-view CNN in a myriad of alternative ways (e.g., transpositions and reshapings). ↩
-
Dynamically modifying the behaviour of an object at runtime for compatibility with other methods is called monkey patching. higher has a similar “monkey patched” transformation of a module to compute meta-loops of optimization. See also #58839 [RFC] Functional API design for torch.nn.Module for some additional comments on this. ↩